- Part 1 - Choosing a Retriever
- Part 2 - Choosing a Model
Hello friends. This is part 1 of a two-part series covering retriever interleaving and summary LLM model selection. In this part our goal is to decide which retriever to use when confronted with multiple engines or configurations.
This is an important article, because when a summary is present less people click on results. This means we have less data to use when iterating on retrieval engines and configurations. Since everyone is showing summaries these days, I outline a pragmatic approach to choosing a search retriever from two or three candidates when using RAG, and how to use interleaving to iterate over configurations with one or more LLMs providing stake in the choice.
Furthermore, I will show that Bing and Brave absolutely TROUNCE Google in a showdown for use as context in a summary, that you need to use multiple pages of results for success, and how to effectively measure outcomes to make retriever decisions. In part 2, I will outline how to select an LLM using the results we gather in this part 1.
First we ask the question: What kinds of search results work best for an LLM during RAG? When asking this, the first thing that jumps into most minds is that of relevance. But the answer is more complex.
When exploring the best solution to this question, comparing outcomes of retrieval engine configurations one at a time with A/B testing poses significant challenges. This is because A/B testing and contrasting metrics deny you of understanding true comparative preference, and unless the same queries are used enough by multiple people, the data is too sparse and you are unable to make trustworthy conclusions.
Interleaving
Interleaving, the process of blending the query results of two or more engines into the same result set, gives us easy to obtain insights into the relevance of search results and the behavior of LLMs for knowledge summaries, and allows us to craft our results to align better with successful outcomes. Interleaving also avoids error prone independent comparisons and long-tail sparsity problems that pop up with A/B testing.
Before we add LLMs into the mix, first we need to describe how interleaving works.
Team Draft Interleaving and credit assignment
Here is a simple illustration and step-by-step overview that show the team-draft interleaving process. Team-draft is a certain type of interleaving, which I first learned from an incredible talk by the Wikimedia search team way back in 2018.
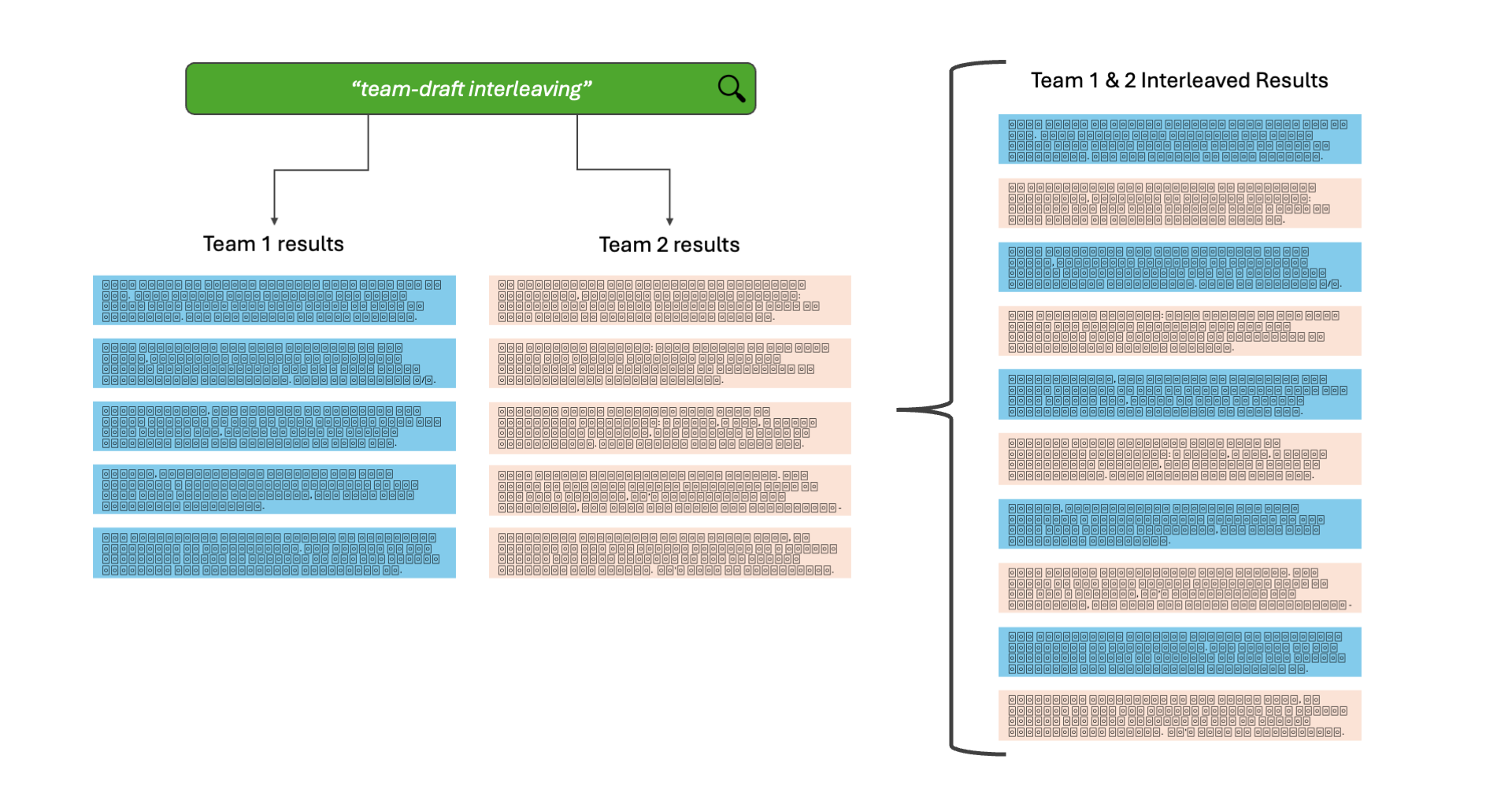
The process:
- We take a search query from a user
- We send the query to two different engines
- We pick a team at random, and add their first result to the set
- We then take the first result of the other team
- If the result was already added by someone, we skip it and take the next
- We alternate picking results from each team until the end of both
- We use that final set as the results to display to the user
This is powerful, because we also make use of credit assignment. If a user interacts with one of the results, we remember which team it came from, and we give that team points. Over some time, with hundreds or thousands of queries, we can tally the points and see which team performs better. Since a winning team represents a search engine configuration, we promote that configuration and use it exclusively until we want to run another test.
Interestingly, interleaving results for LLMs presents a comprehensive solution to not only tune and measure actual relevance, but also tune perceived relevance.
Perceived Relevance
The difference between actual vs perceived relevance is fascinating. The former is the empirical truth of whether or not the result contains the information necessary to satisfy the query. Perceived relevance on the other hand, is whether or not the person looking at a search result can tell whether or not it likely contains the answer. It’s easy to understand when we’re shown a picture.
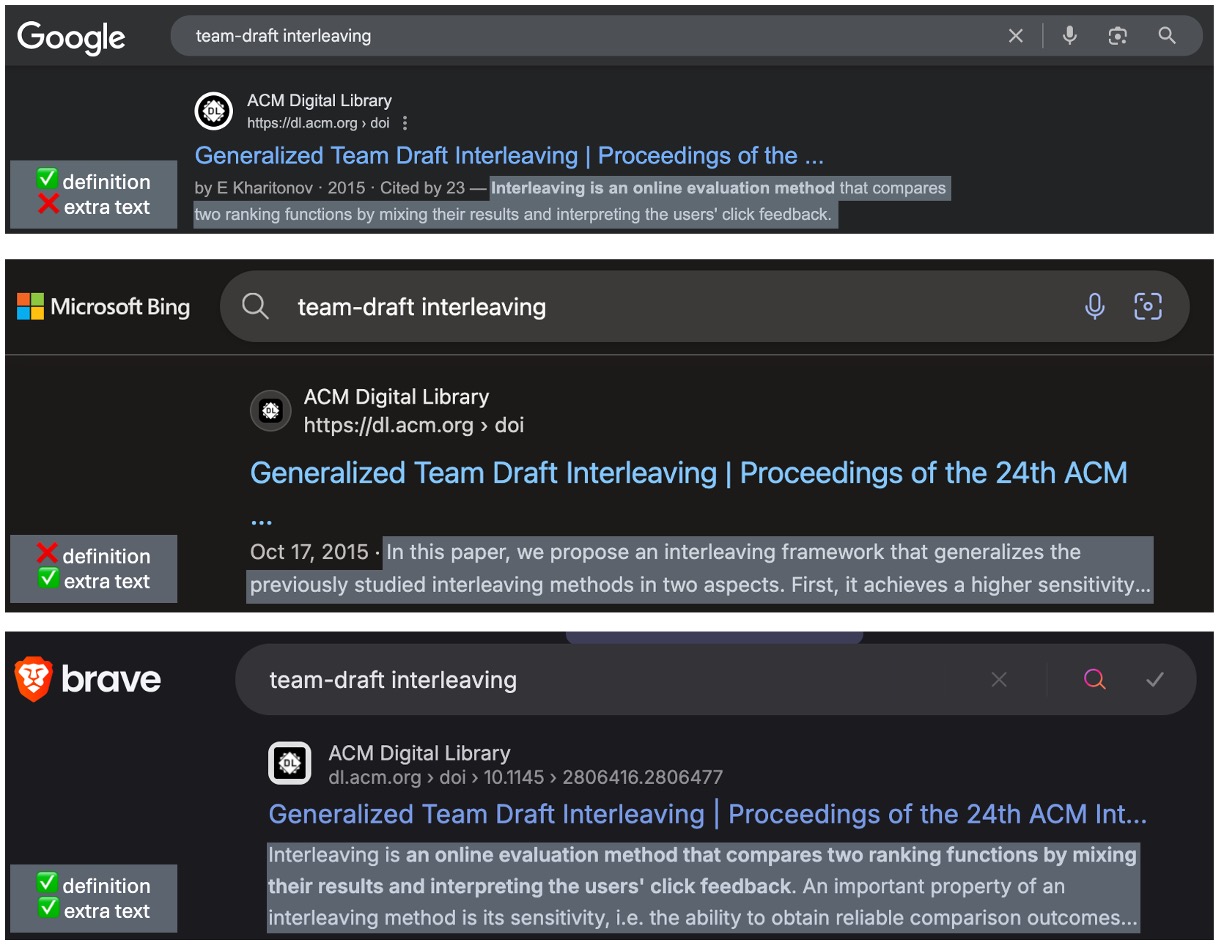
Figure 2: Which result would you choose for the query?
Before we were all spoon fed summaries en masse at the top of our results, we actually had to look at results and make decisions with our brains. Optimizing perceived relevance is key to making this easy for us by showing concise information about the results so we can decide what to click.
To illustrate the benefits of perceived relevance, consider an extreme example: imagine you are only presented with a list of page links as search results with no other data. Assume these are in varying order of relevance with at least one or more containing the information you need. How can you tell which are relevant? You have to click on every result until you see the answer. This example has poor perceived relevance.
Now another extreme: each result in the list shows the entire document and you are presented with thousands of sentences to exhaustingly scroll through while hunting for what you need. This is also poor perceived relevance because again, it is difficult to tell immediately and requires significant effort.
Compare these extremes with what is typically presented: a title, a url, a short contextual snippet, and perhaps a date of publication. This allows one to scan the results and make a very quick decision on which is best before continuing further:
Google, Bing, and Brave all provide clear information that gives you enough information to make a decision on whether to click on the result. Only two snippets provide exactly the definition for the term, and only two provide extra text. You can already see where this is going. In this case, Bing’s snippet will be useless to an LLM for summarization.
Snippets for LLMs
LLMs behave differently than people. And while we can drop entire documents into an LLM for a summary, it’s unnecessary and expensive, and will add noise and irrelevant information - especially for trivial queries. So we look to optimize what to gather for context when summarizing a list of results. In essence we need a concept of perceived relevance for LLMs.
In general, the following holds: longer snippets yield better summaries. They reduce hallucinations and improve coverage of the answer. However if the snippets are too long, noisy tangential or irrelevant information can creep into the summary.
Additionally, while there are plenty of LLM-as-a-judge theses out there, I posit that doing this separately is a waste of time for RAG. LLM summaries work perfectly fine over dozens of results en lieu of a well tuned top list of 4 or 5. In effect, extreme relevance tuning becomes less important when a summary is presented, because the LLM skips the irrelevant results for you. Thus, when validating the quality of a RAG summary with citations, you also get judgements as a bonus.
We consider these two areas: optimizing context and tuning result relevance, by interleaving results and scoring the summary. This yields important information and enables you to naturally gravitate to the best retrieval configuration.
One more illustration (Figure 3) before diving into the experiment, contrasting the approach of A/B testing versus Interleaving for RAG. The benefit becomes clear: the LLM will give credit assignment for the interleaved results when cited, compared to A/B testing which is much harder to measure for RAG. In A/B testing the summaries will be different for each team, leaving you wondering what the summary would be when the LLM is presented with both sets at once.

Experiments for web search summaries
I present the following evidence in the context of RAG for web search. I used 976 actual search queries, three interleaved engines of Google, Bing, and Brave as retrievers, and four LLM models ( Claude Haiku 3.5, Claude Sonnet 4, GPT-4.1, and GPT-4.1-Mini ) for summarization. We know that these three engines are already tuned for relevance, and we know these models are state of the art for summarization. We can cross compare them by observing the outcome of the LLM summaries.
The search queries were captured over the past 6 months by users in their casual use of a research engine I built. They are all from anonymous sources and I scrubbed them of PII (which were mostly vanity searches - you know who you are!). The queries were primarily in English, with a handful of German, Polish, Hebrew, and Armenian. Overall they were a mix of technical, medical, legal, general research, and trivial queries. To remove bias I excluded news, politics, sports, and anything I found to be spicy. I was left with a nice set of 976 unique and real queries from dozens of actual people. I will note potential bias in the query list, in that the engine is primarily used by me, and my queries account for just more than half. Even with this note the queries were always in real scenarios for my actual day-to-day use and not tests.
An example result from the platform is displayed in Figure 4. The interleaved results for the three engines are on the left, and the summary on the right. The 27 interleaved results are cropped down to 6 in the image.
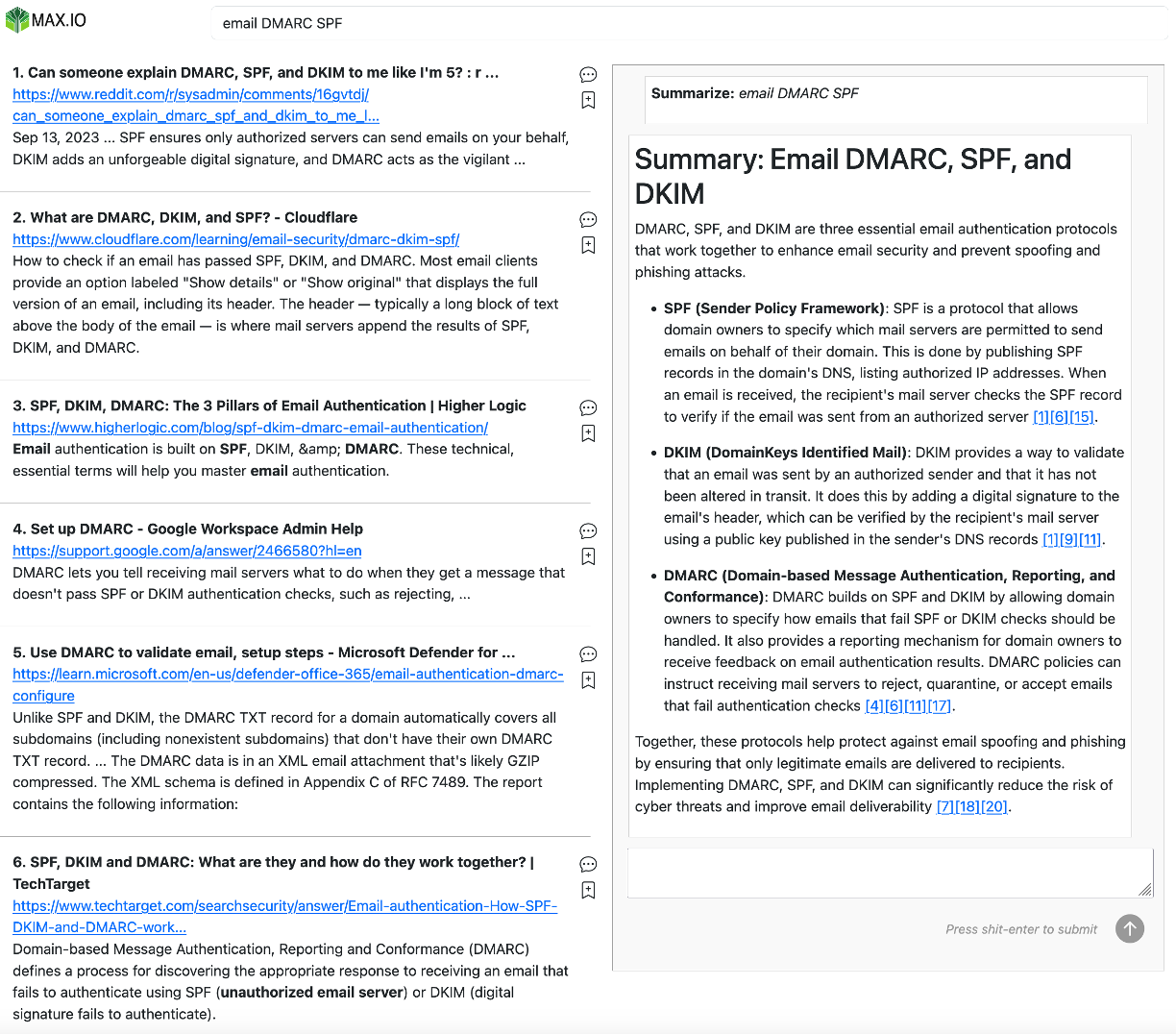
Figure 4: one of the platform examples in the query set “email DMARC SPF”, shows interleaved results from the three engines on the left, and the summary with citations in blue on the right.
Here is the process:
- A query is run against all three engines Google, Bing, and Brave.
- None of the engine results contain ads, as I used their official paid APIs to avoid them.
- The results are combined into a single set using team-draft interleaving.
- Each positional result in the interleaved set maintains its source engine name for credit assignment later on.
- The interleaved results are formatted into a summary prompt template.
- The prompt is sent to the LLM and the output streamed back to the system.
- The output contains summary passages with citations of the search results.
- A citation assigns credit to the engine that provided the result.
- The process is repeated for all 976 the queries in the list and the outcomes tallied.
Results
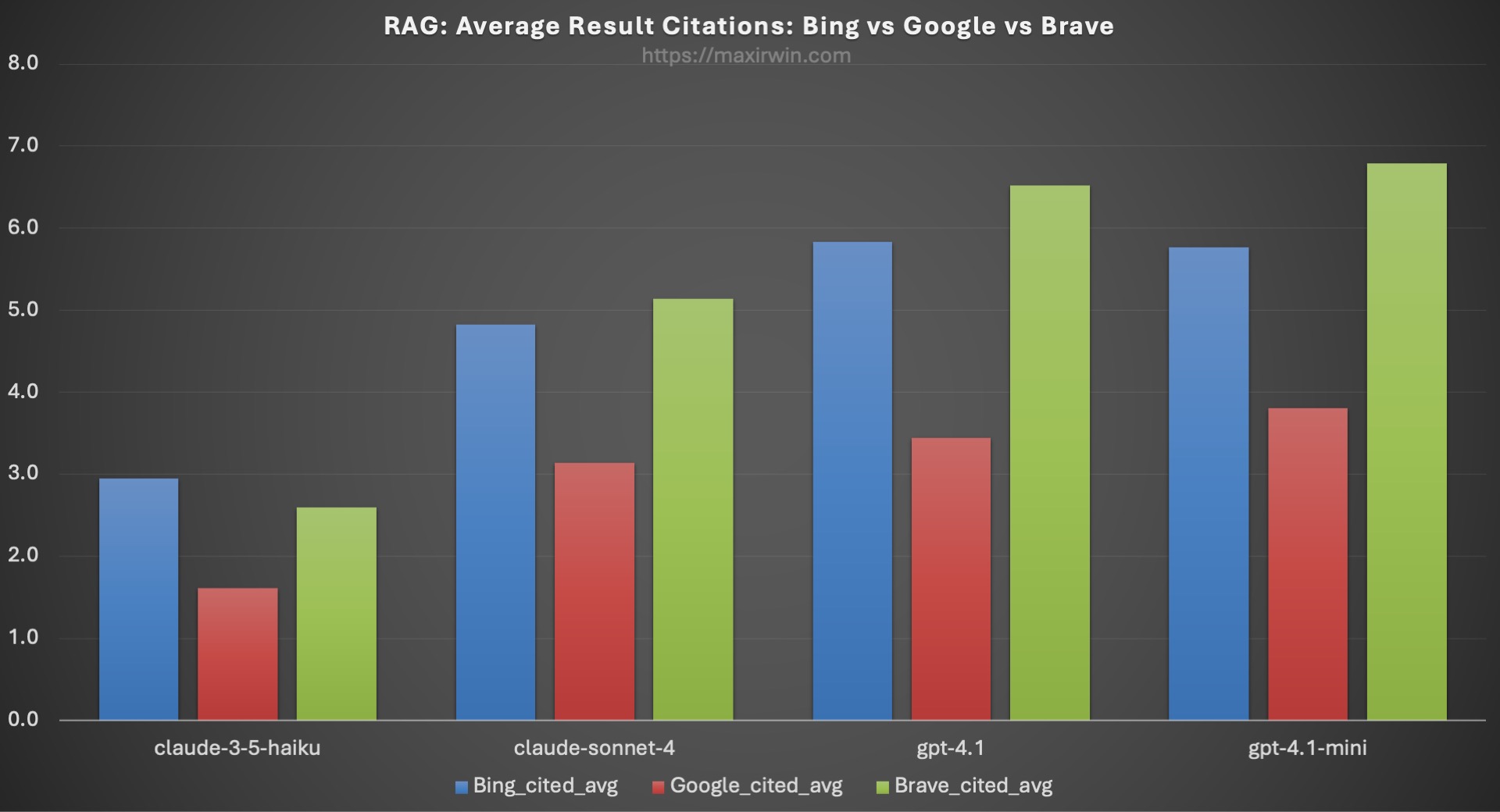
Figure 5: Average credit assignment of citations to the respective retriever across all 4 models.
In Figure 5, we can clearly see the engine with the most citations is Bing by a significant margin, followed by Brave, and deeply lagging in third is Google.
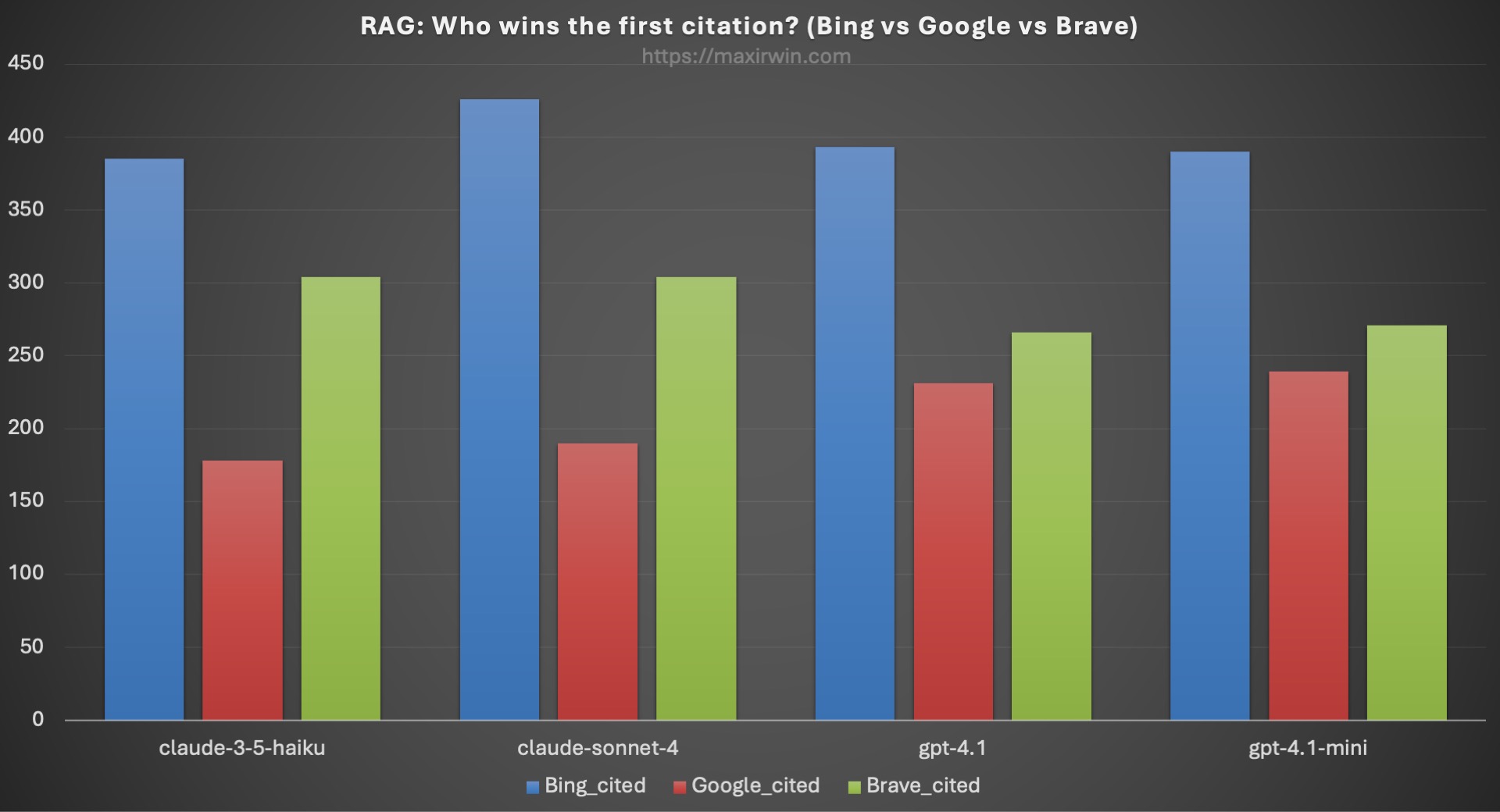
Figure 6: First only credit assignment of citations to the respective retriever across all 4 models.
Figure 6 shows results for who got cited first (and then stops). This only takes the first citation found in the summary and assigns credit to the engine that provided it. Again, the difference is clear with Bing far in the lead - however GPT has Google in a closer second place. An important note: all three had an equal chance of appearing as the first result in the list due to team-draft selection, and Bing still overcomes this by a wide margin.
Why is Google so far behind? Do we not assume that it is the world’s best search engine? The answer becomes clear when we dig: for all results across all searches, the average length of a Google result snippet is 155 characters, while the average lengths of Bing and Brave are 293 and 253, respectively. This is the analogous “perceived relevance” for LLMs, but really it’s just that there isn’t enough context available for the model to use when generating the summary. This comparison is illustrated in Figure 7.
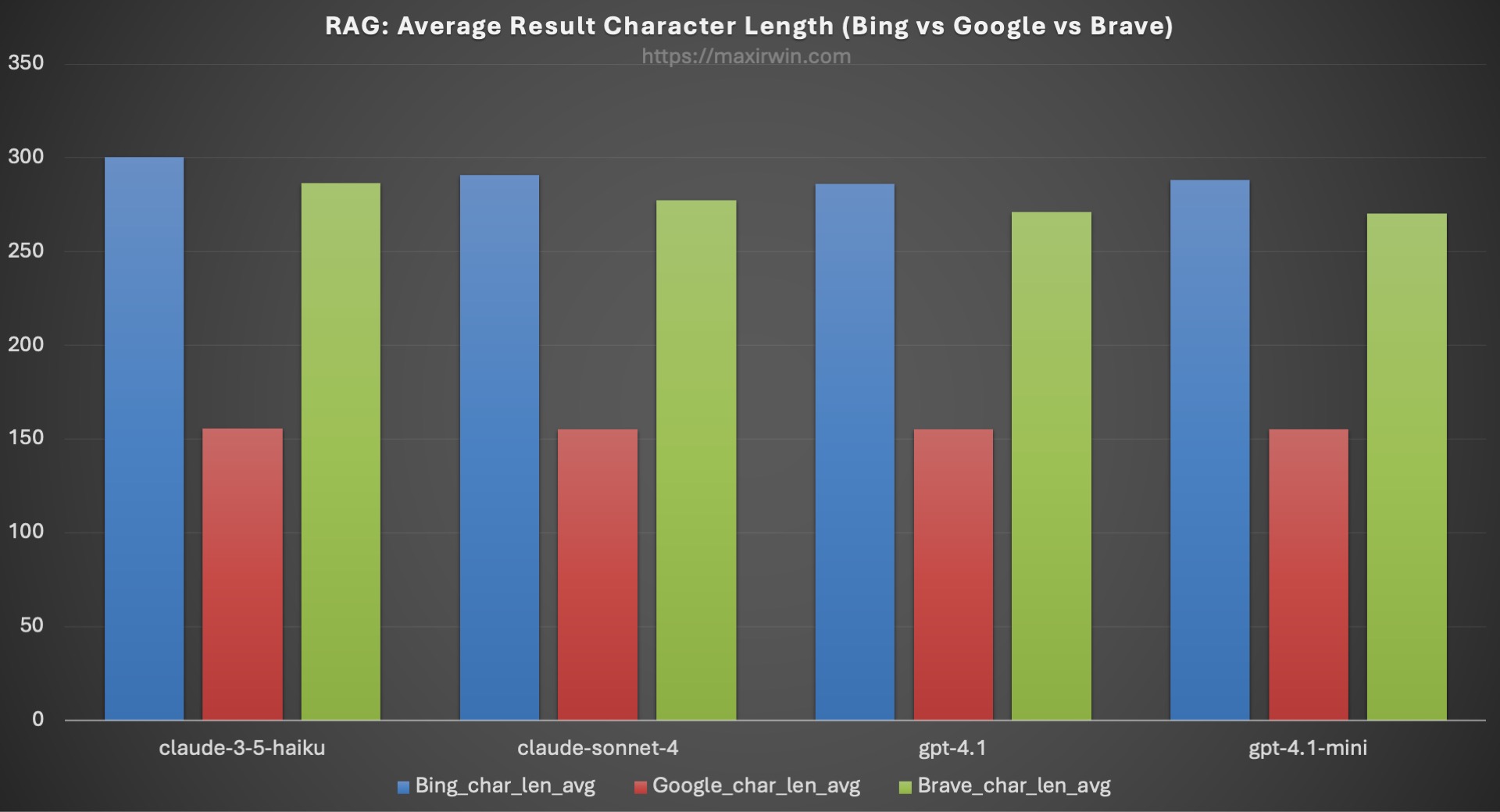
Figure 7: Average character length (in bytes) for each engine’s snippets
This shows a direct correlation. The shorter snippets are very likely responsible for the LLM to pass over Google in favor of Bing’s and Brave’s longer snippets. Note the snippet length is only counted for results that are cited in the summary. Table 1 contains the raw numbers for Figures 5, 6, and 7.
| Bing | Brave | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| model | type | cited | cited_avg | char_avg | cited | cited_avg | char_avg | cited | cited_avg | char_avg |
| claude-3-5-haiku | Once | 2872 | 2.9 | 300.3 | 1575 | 1.6 | 155.6 | 2529 | 2.6 | 286.8 |
| claude-3-5-haiku | First | 3929 | 4.0 | 304.8 | 1831 | 1.9 | 155.7 | 3115 | 3.2 | 292.1 |
| claude-sonnet-4 | Once | 4709 | 4.8 | 290.9 | 3064 | 3.1 | 155.1 | 5019 | 5.1 | 277.4 |
| claude-sonnet-4 | First | 7841 | 8.0 | 298.7 | 3974 | 4.1 | 155.6 | 7099 | 7.3 | 286.1 |
| gpt-4.1 | Once | 5691 | 5.8 | 286.2 | 3357 | 3.4 | 155.1 | 6370 | 6.5 | 271.3 |
| gpt-4.1 | First | 13455 | 13.8 | 292.6 | 6206 | 6.4 | 156.0 | 13385 | 13.7 | 281.6 |
| gpt-4.1-mini | Once | 5631 | 5.8 | 288.3 | 3709 | 3.8 | 155.2 | 6630 | 6.8 | 270.4 |
| gpt-4.1-mini | First | 11276 | 11.6 | 293.4 | 6170 | 6.3 | 155.7 | 11753 | 12.0 | 278.1 |
Table 1: search result citations and snippet length per model and method, for 976 search queries
Cited Position Analysis
We can also garner some keen insights on relevance from a histogram of result positions cited, regardless of engine. My research application uses lots of results for RAG. Upwards of 40. I do this because I learned early on in its development that relevant results often appeared past the first page of 10. This is illustrated with histograms of cited position for each model. You can clearly see that >10 holds significant input.




Spicy takes: 🌶️ The summaries of Google, Bing, and Brave in their own sites fall short because they assume all the good stuff is at the top. It’s not. You must dig deep. There’s gold buried on the 2nd and 3rd pages! In addition, agents using web search such as ChatGPT only look at the top several results from Google before making a decision on what to download and include in a deeper context inference. They produce mediocre research due to this lack of depth in scope.
Conclusions
To recap, use the following lessons when building RAG or a research agent:
- Make your snippets longer for the LLM, because cutting them short may leave critical information out of the summary.
- Don’t worry too much about the top 5 documents, and give your LLM several pages of results. You can reorder the result on the page according to citation order. This will vastly improve the outcome, and we saw that even the best tuned engines don’t cut it on the first page.
- Iterate and tune by interleaving different versions of your retriever configuration and see which works best for the LLM.
I propose in fact, having two snippet versions per result: one for people and one for LLMs. Show the former in the result list on the page, and use the latter for your RAG prompt template.
Up next, in part 2 “Comparing Models for RAG”, I show how to choose one of the four models by leveraging our interleaved results and a set of metrics.
Also I’d like to as a favor - please share this article! Get in touch with me on LinkedIn if you are interested in discussing more, or if you’d like some help integrating these or other techniques into your products.
Obituaries
On Monday August 11th, 2025, Microsoft killed the Bing Search API. This was largely ignored by the technical community, but the death of this product has an outsize impact on the quality of augmented web knowledge applications.
You can use it as part of “grounding” for their agent API in Azure - but it removes the flexibility that I and many others need (and it’s very expensive). This leaves Brave. Their coverage of the web is not as good as Bing (I estimate 1/5th the scope), but otherwise a decent contender and they have very favorable API terms.